OLTP vs. OLAP — What’s the Difference?


There are two major camps in the relational database development world: OLTP and OLAP. In this post, we consider the differences and similarities of these two systems.
First of all, both OLTP (on-line transactional processing) and OLAP (on-line analytical processing) are used in business applications, especially — although not exclusively — in data warehousing and analytics. Together, they form the two different sides of the analytics/warehousing coin: storing and manipulating the data on one hand and analyzing it on the other.
Entering the database world, it is important that you have a clear grasp of the different flavors of database usage. No matter which direction you choose to take, understanding the basic differences between OLAP and OLTP will serve you well. The building blocks are the same — SQL and database development. In this article I’ll explain what each type of system does and how each is used.
What is OLTP?
On-line transactional processing (OLTP) is a mouthful to say, but the concept is not hard to grasp. OLTP systems are “classical” systems that process data transactions. They are all around you. In the bank, the ATM or the computer system used by the bank teller to record a transaction is an OLTP system, usually a database. If you text someone from your smartphone, you are working with another OLTP system. The cash register at your local supermarket runs off another OLTP system, and on it goes.
In short, most business applications are OLTP systems. It is hard to imagine a strata of computer engineering that doesn’t have some form of OLTP. In fact, a whole branch of computer science grew up around the need to handle transactions in an orderly manner.

Thus we come to the critical part of the OLTP acronym: the T, which stands for transactional. Transactions are hugely important, and keeping them organized is also hugely important.
What does it take to keep transactions organized? It means that database transactions have to be stable (or durable, not easily changed), isolated, consistent, and atomic. According to Wikipedia, atomicity is an “indivisible and irreducible series of database operations […] that either all occur, or nothing occurs”. In computer science, these are known as ACID transactions (atomic, consistent, isolated, durable). Explaining them in detail is outside the scope of this article, but you can easily learn more by Googling “ACID transactions”.
In simple words, this type of transaction ensures that operations performed by different users do not interfere with each other. For example, if a husband and wife each make a withdrawal from their joint bank account, atomic transactions make sure that they do not withdraw more than their account holds.
An OLTP system needs each of these properties to ensure that everything is working in an orderly manner. When you bank, you are confident that the money you deposit is credited to your account, not mixed up with your other transactions or, heaven forbid, lost.
Clearly, transactional processing is very important for our society as a whole. But what about OLAP?
What is OLAP?
OLAP is short for on-line analytical processing. The key letter here is A for analytical, which also tells us what the OLAP system does. An OLAP system analyzes data effectively and efficiently.
Unlike OLTP, OLAP systems work with very large amounts of data. Preserving the accuracy and integrity of transactions is not their purpose; this is up to OLTP. OLAP is here to allow us to find trends, crunch numbers, and get the big picture. These systems have a smaller group of users than OLTP systems. For example, you will not interact with your bank’s OLAP system, since it is not concerned with recording your account transactions.
As OLAP’s number-crunching usually involves a large data set, the interactions last longer. And there are many situations where we won’t know what the interactions (SQL queries) will look like beforehand. A few queries may be small, but the majority are usually quite sizeable and take a long time to execute. In contrast, OLTP systems use common commands like INSERT and DELETE, so we have a pretty good idea of what the end result will be. And it shouldn’t take too long, either.

The size of the system also plays an important role in OLTP and OLAP systems. OLTP must be stable and fast (to accommodate all that real-time work), while OLAP must be large enough and powerful enough to capture all the relevant business data.
OLTP vs OLAP
Let’s examine the differences between OLAP and OLTP using realistic examples.
A Real-World OLTP Example
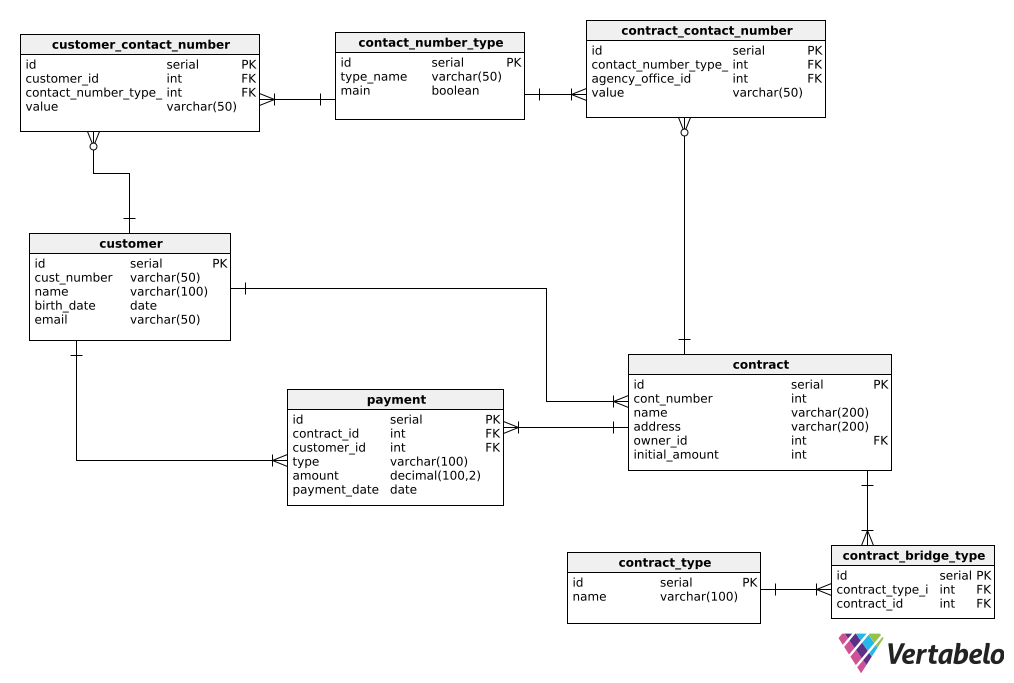
Remember, OLTP queries are much simpler and smaller than those used in OLAP systems. We need to execute OLTP queries quickly and for a small number of rows. For this example, we will look at a simple OLTP financial payments model.
Right away, we can see some basic tables containing customer data, contract data, and records of completed payments. We also see tables storing contact data and a bridge table called contract_number_type. Another table defines contract_types (i.e. savings accounts, checking accounts, etc.), while the contract_bridge_type table contains bridged data.
The model is normalized in 3NF. To learn more about various database normalization, please see this post.
In an OLTP system, data is acquired in small “batches”. The best analogy for this process is a highway with lots of small, fast sports cars buzzing along in perfect harmony and not interfering with one another.
When inserting new data into an OLTP system, we usually work with one small set of records at a time. Also, we need to make sure that any changes to these records will not affect other records. For example, suppose we are entering a customer’s payment into the database. First, we would verify that the customer account is there. Then, we would enter the payment amount, date, and other info. When designing an OLTP system, we need to think about processing frequent, small chunks of data. And we have to be able to support many users at one time.
Referring to our financial model, let’s say we need to insert a payment of $5,000 into account number 1112 for a customer with the ID of 11. Here’s the code to make that happen:
As this transaction is being processed, there are many other transactions being performed at the same time. In a properly-designed OLTP system, this presents no problem. No “car crashes” ever occur, everything is moving along smoothly, and the OLTP highway has just the right traffic flow.
Here we go again❗🤪 Let's lean back to 15 top-rated #SQL blogs for beginners published in 2017 👉 https://t.co/Abs1gUBoDu
thx to @MarkusWinand @be_haki @JavaOOQ @mafiswana @SQLShack @TDAN_com @YhatHQ @sqlstudent144 @MydbopsOfficial #Data #Databases #MySQL #SQLserver #BigData pic.twitter.com/ca9CfyKYTO
— Vertabelo Academy (@VertabeloAcdm) May 30, 2018
Now let’s take a look at a typical OLTP query, which displays data relevant to the user at an atomic level. Suppose someone with the customer ID of “11” wants to see their last ten transactions:
SELECT
payments.*
FROM (
SELECT
ROW_NUMBER() OVER (ORDER BY payment_date DESC) AS rows,
p.*
FROM payment p
WHERE customer_id = 11 ) payments
WHERE rows <= 10

Or perhaps the same customer wants to see what contract information is on file at the financial institution:
SELECT contracts.* FROM contract ctr JOIN customer cst ON ctr.customer_id = cst.id WHERE cst.id = 11
The important thing to remember here is that the queries that are working with the model are small, fast, and atomic.
A Real-World OLAP Example
Let’s look at the same example in a different context: as an OLAP model. OLAP models are most commonly used to support reporting and analytics.
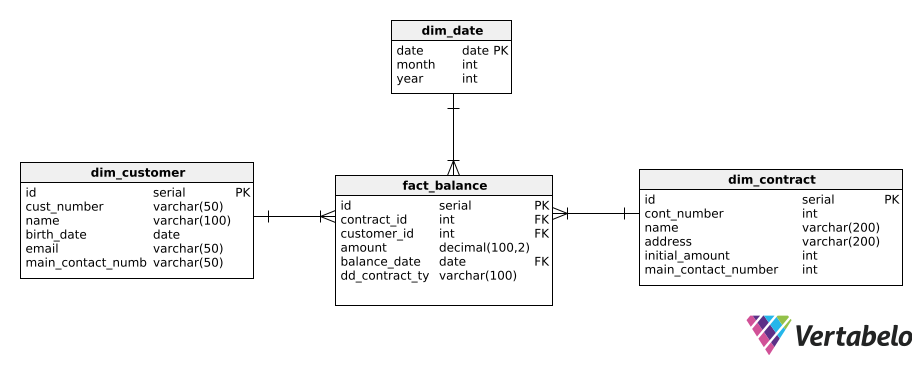
This model is a simple star schema; to learn more about the star schema in data warehouse modeling, see this Vertabelo blog post.
In the model, we see three dimensional tables: dim_customer for customers, dim_contract for contracts, and dim_date for date data. There is one central fact table, fact_balance. This table contains balance information for specific dates. Again, refer to this Vertabelo blog post to learn more about fact tables.
Data isn’t entered into OLAP models in the same way as OLTP models. Rather than getting information a bit at a time as it comes in, OLAPs are filled by batch queries that scan the entire source model (usually an OLTP system) and import the data into the OLAP model. Obviously, the INSERT statements for OLAP are larger and slower because they include multiple source tables. The process of filling the OLAP system from the source systems is called ETL (extract-transform-load).
Let’s create a simple ETL query to fill one of the tables of our OLAP model — in this case, the dim_customer table:
INSERT INTO
dim_customer(
id,
cust_number,
name,
birth_date,
email,
main_contact_number)
SELECT
seq.nextval,
cst.number,
cst.birth_date,
cst.email,
ccn.value
FROM customer cst
RIGHT OUTER JOIN customer_contact_number ccn
ON cst.id = ccn.id_customer
JOIN contact_number_type cnt
ON ccn.customer_type_id = cnt.id
WHERE cnt.main = True;
As you can see from the query, we are utilizing multiple tables to fill the dimensional table. This kind of complexity is usual for OLAP queries.
We could fill the dim_contract table in the same way. However, we won’t fill the dim_date table, as it is predefined in the database and its dates do not change. As for the fact_balance table, the process of filling it is far too complex for this article. At this point, all we need to know is that fact_balance holds snapshots of customer data (i.e. account balances) at specific date intervals.
If OLTP is a smoothly-running highway with lots of similar cars, an OLAP highway is a chaotic place with large strange vehicles moving at different speeds. It is not uniform in any sense of the word: there are large slow cars which nobody has seen before (ad-hoc queries), large slow cars that we see often (monthly reports), and other beasts.
A typical example of an OLAP query would show the average balance every third month for all users:
SELECT avg(amount) FROM fact_balance fb JOIN dim_date dd ON fb.balance_date = dd.date WHERE dd.month = 3;
Another OLAP query could show the aggregated sum of all customers born after 1990:
SELECT
avg(amount)
FROM fact_balance fb
JOIN dim_customer cst
ON fb.customer_id = cst.id
WHERE EXTRACT(month from balance_date ) = 3
AND birth_date >= date('01-01-1990','dd-mm-yyyy');
Incoming OLAP queries are usually aggregated and take into account all of the data of a specific subset. So we are looking at trends, averages, aggregations, etc. These queries can take a lot of time, depending on the size of the subset we are exploring and therefore are not uniform (as OLTP queries are).
I hope that this article has helped you to understand how OLTP and OLAP systems are different from each other, and also how they work together. Please feel free to ask any questions or share your thoughts in the comments section.




