7 Effective Ways to Deal With Small Dataset


In a real-world setting, you often only have a small dataset to work with. Models trained on a small number of observations tend to overfit and produce inaccurate results. Learn how to avoid overfitting and get accurate predictions even if the available data is scarce.
Big data and data science are concepts often heard together. It is believed that nowadays there are large amounts of data and that data science can draw valuable insights from all these terabytes of information. Indeed, it can!
However, in a practical scenario, you will often have limited data to solve a problem. Gathering a big dataset can be prohibitively expensive or simply impossible (e.g., only having records from a certain time period when doing time series analysis). As a result, there is often no choice but to work with a small dataset, trying to get as accurate predictions as possible.
In this article, we’ll briefly touch on the problems that arise when working with a small dataset. Then, we’ll discuss the most effective techniques to overcome these problems.
Bias-Variance Tradeoff
In a nutshell, when you are searching for a perfect model to explain your data, you are balancing bias and variance.
Bias is the difference between the model’s prediction and the true value. Models with high bias oversimplify the relationship between predictors and a target variable and demonstrate high error on both training and test data.
Variance reflects the variability of the model prediction. Models with high variance pay too much attention to training data and do not generalize well to a test dataset. As a result, these models show very low error on a training set and very high error on a test set.
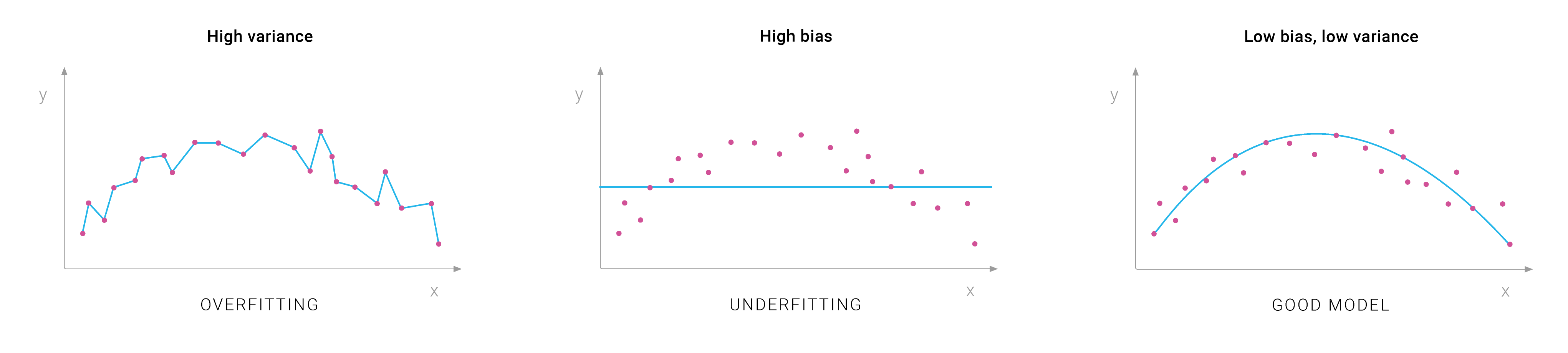
Overfitting vs. Underfitting vs. Good Balance (source)
Models with low bias and high variance overfit the data, while models with high bias and low variance underfit the data.
Models trained on a small dataset are more likely to see patterns that do not exist, which results in high variance and very high error on a test set. These are the common signs of overfitting. So, your main goal when working with small datasets is to avoid overfitting.
How do you do this?
Techniques to Overcome Overfitting With Small Datasets
We’ll now discuss the seven most useful techniques to avoid overfitting when working with small datasets.
-
Choose simple models. Complex models with many parameters are more prone to overfitting:
■ If you’re training a classifier, consider starting with logistic regression.
■ If you’re training a model to predict a certain value, consider a simple linear model with a limited number of weights.
■ For tree-based models, limit the maximum depth.
■ Use regularization techniques to keep a model more conservative.
With scarce data, your goal is to limit the model’s ability to see non-existent patterns and relationships. This means that you want to limit the number of weights and parameters and rule out all models that imply non-linearity or feature interactions. Also note that according to research, some classifiers might be better at dealing with small datasets.
- Remove outliers from data. When using a small dataset, outliers can have a huge impact on the model. So, when working with scarce data, you’ll need to identify and remove outliers. Another approach can be to use techniques that are robust to outliers like quantile regression. Removing the impact of outliers is essential for getting a sensible model with a small dataset.
- Select relevant features. Usually, explicit feature selection is not the best approach, but when data is limited, this might be an essential step. It’s hard to avoid overfitting with a small number of observations and large number of predictors. There are several approaches to feature selection, including analysis of correlation with a target variable, importance analysis, and recursive elimination. It is also worth noting that feature selection will always benefit from domain expertise. So, if you are not familiar with the subject area, find a domain expert to discuss the process of feature selection.
Combine several models. When you combine results from more than one model, you may get much more accurate predictions. For example, a final prediction calculated as a weighted average of predictions from various individual models will have significantly lower variance and improved generalizability compared to the predictions from each individual model. Furthermore, you can combine predictions from different models or from the same model using different values of hyperparameters.
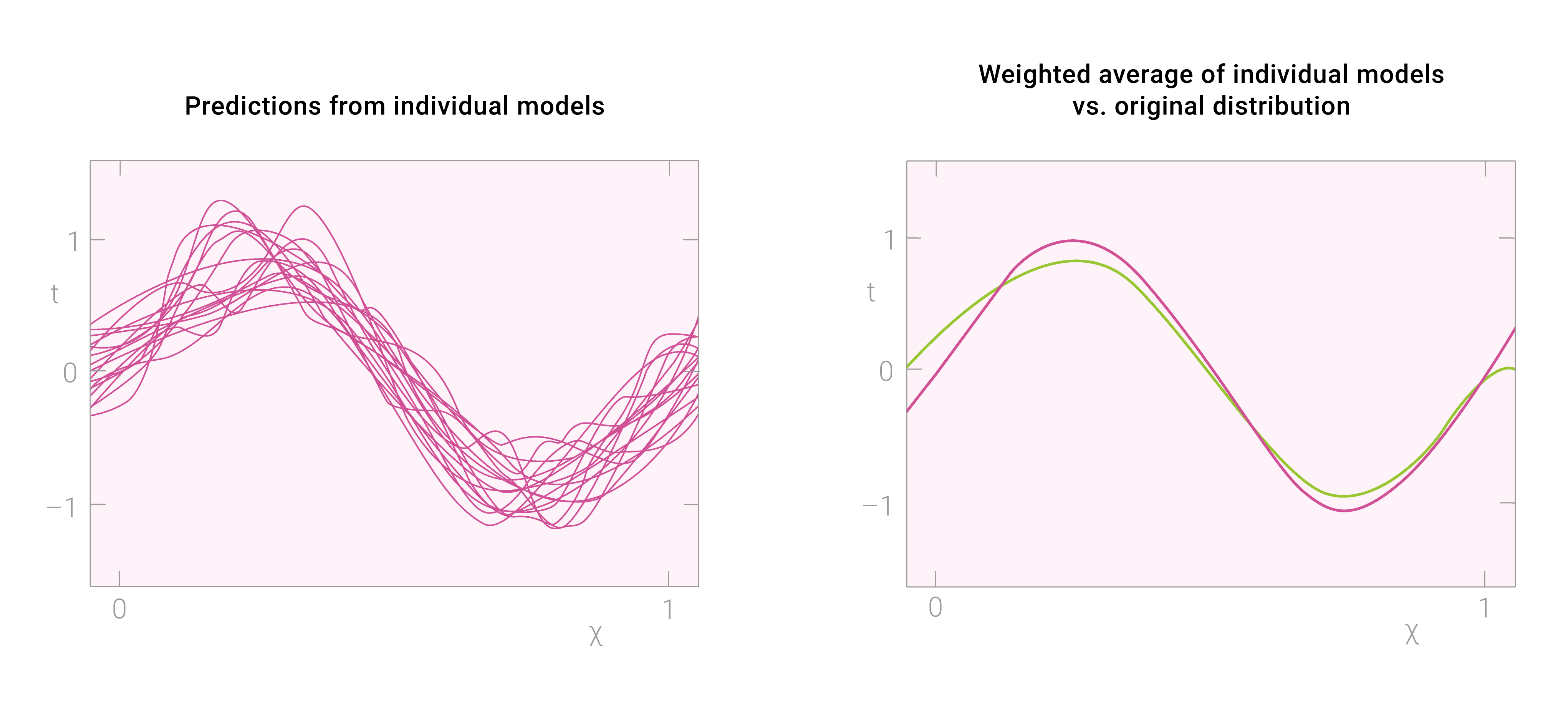
Combining predictions from several models (source)
Rely on confidence intervals instead of point estimates. It’s often a good idea to estimate confidence intervals for your prediction in addition to the prediction itself. This becomes especially important when you’re working with a small dataset. So, in regression analysis, make sure to estimate a 95%-confidence interval. If you’re solving a classification problem, calculate the probabilities of your class predictions. When you have a better understanding of how “confident” your model is about its predictions, you are less likely to come to the wrong conclusions based on the model’s results.
-
Extend the dataset. When data is really scarce or the dataset is heavily imbalanced, search for ways to extend the dataset. For example, you can:
■ Use synthetic samples. This is a common approach to address the underrepresentation of certain classes in a dataset. There are several approaches to augmenting a dataset with synthetic samples. Choose one that best fits your particular task.
■ Pool data from other possible sources. For instance, if you’re modeling temperature in a specific region, use weather information from other regions as well but assign a higher weight to the data points from your region of interest.
Apply transfer learning when possible. This approach is also a type of data extension. Transfer learning implies training a universal model on available large datasets and then fine-tuning it on your small dataset. For example, if you’re working on an image classification problem, you can use a model pre-trained on ImageNet, a huge image dataset, and then fine-tune it for your specific problem. Pre-trained models are more likely to produce accurate predictions than models trained from scratch using limited data. Transfer learning works particularly well with flexible deep learning techniques.
Small Data Is Just Another Challenge That You Can Overcome!
Many researchers and practitioners believe that small data is the future of data science. It’s just not feasible to have huge datasets for every kind of problem. Follow these guidelines to overcome the challenges of a small dataset:
- Understand the basics of statistics to know what kind of issues you can expect when dealing with a small number of observations.
- Learn the key strategies to avoid overfitting and get accurate results from small data.
- Conduct all data cleaning and data analysis steps efficiently (e.g., using Tidyverse in R language or Python tools for data science).
- Be aware of the model’s limitations when drawing conclusions from its predictions.
If you lack some of the knowledge needed to deal with small data, there are some great online courses available. With Vertabelo Academy, you can learn basic statistics and data analytics through engaging interactive exercises.





