Agile Data Science: Improving Your Workflow with Scrum


Within organizations, Scrum promotes efficient time and process management along with better team building and leadership. In order to implement Scrum, you’ll need to follow a few simple rules.
Introducing Scrum
Today, we have the power to collect precise data both quickly and in vast quantities. In fact, 90% of the data available today was collected in the last two years alone. The rise of big data has greatly increased demand for data scientists, but the profession is one where few candidates possess the right skills. This, however, can be remedied.
Scrum is a comparatively lightweight subset of the Agile Manifesto; it’s is a development framework that emphasizes a quick, iterative, and productive workflow. Most commonly used in software development, Scrum significantly increases productivity and reduces the time it takes to finish a product.
Scrum Requirements
Scrum is a flexible framework based on specific concepts and practices that can be divided into three categories: Roles, Artifacts, and Activities (sometimes referred to as Timeboxes).
The requirements for a project are outlined by user stories, which are written by the developers from a user’s perspective to describe (in simple language) the features that the final product should have.
User stories can be both product and user oriented. All stories refer to the work that needs to be done within a given timeframe.
There are three roles defined by the Scrum framework.
- Product Owner: the individual who has a vision for the final product and who develops a product backlog with a comprehensive list of features that the final product should have.
- Scrum Master: ensures that the project progresses smoothly and that every member of the development team has the tools they need to get their job done. Meetings, management, and release planning are also covered by the scrum master.
- The Team: a self-organizing and cross-functional group of professionals who do the hands-on work to develop and complete a project.
The Scrum Process

Source: http://www.stigasoft.com
In Scrum, all projects follow a series of iterations called sprints. A sprint can vary in duration from just 2 days to 4 weeks, depending on the size of the release. During a sprint, members of the development team participate in daily scrum meetings of roughly 15 minutes to share and assess progress.
Based on this meeting, a burndown chart is maintained to track and communicate how much work remains in a particular sprint. Upon completion of a sprint, the review and retrospective meetings are held to evaluate the effectiveness of the sprint.
In short, the goal of a sprint is to produce a potentially shippable product increment—a working product that perhaps does not yet have all the features that the product owner envisioned.
By now, it should be clear that implementing Scrum streamlines workflow management and improves productivity. So how does this help a data scientist’s workflow?
The Data Scientist Scrum Workflow
Data by itself is idle and requires a trained professional who can make sense of it and churn it into usable data. And that’s where data scientists come into play. A data scientist filters through the mass of data, searches for patterns, and identifies key metrics that can help a business or organization make informed decisions.
Like professionals from other fields, data scientists also follow certain processes in their workflow. However, there’s room for improvement. Let’s take a look at the standard data scientist workflow.
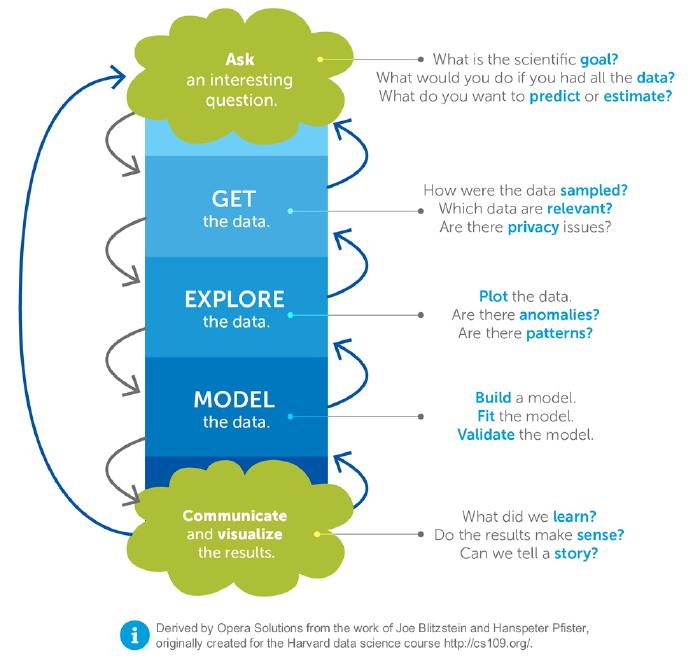
Source: http://www.statsoft.org
The process involves asking the right questions, acquiring and analyzing the data, building relevant models, testing the results of the analyses, and making observations. It’s just as difficult in practice as it is simple in theory.
Acquiring and filtering data for analysis is a time-consuming process. But it becomes fairly easy when you divide each step into a separate task or role. This is where Scrum shines.
The Big Answer
The practice of data science is complex—and while data scientists are not the primary practitioners of Scrum, an understanding of both Scrum and data science leads to an interesting observation:
Assuming that a set of questions asked is a single project, the Scrum model dictates that this set be considered a backlog. Each question guides the data science workflow, so we relegate each step in the process to a specific job role.
Sprints are planned to answer each question. Members of the team are assigned to the task of collecting the relevant data sets to a question as part of the first step. The collected data sets are then filtered, and usable data is sent off to the next step, where assigned teammates plot the data and explore it for relevant patterns and anomalies.
Based on the analysis, the team then builds a working model of the data and observes the results of its implementation. The resulting report is then visualized by another set of teammates to communicate the observations of the valid model.
Each team member assigned to the task follows the timebox relevant to their job role. The burndown chart tracks the amount of time it will take to answer the question, while highlighting key measures that could reduce the same. All tasks mentioned above can be part of every data scientist’s personal workflow, where each task in the workflow follows a fixed timeline on the burndown chart of a particular sprint or iteration.

Conclusion
The concept of applying Scrum to a data scientist’s workflow could not only save considerable time in answering the right questions but also help answer more questions in less time. Here’s a summary of the key points we discussed in this article:
- Scrum is a process management tool used in the development of high-end software.
- Scrum involves identifying the work to be completed, managing the developments through sprints, tracking work with burndown charts, and assessing the results during Scrum meetings.
- The data science workflow involves asking the right questions, filtering data, exploring relevant data, building working models, and communicating results.
- The Scrum model provides an excellent framework for a data scientist’s workflow.


