Instruction
Good job! You may have noticed two interesting things.
1. Because both datasets contained a column named items_sold, pandas had to find a way to distinguish between them. It did it by renaming one of the columns to items_sold_x, and the other one to items_sold_y.
2. Only data from the years 2013-2015 were shown. Those years were the only periods when both store_a and store_b were open. Before 2013, there was only data for store_b. After 2015, there was only data for store_a. This type of merge is called an "inner merge". If, instead, you want to see all data from both files, you should use an "outer" merge in the following way:
stores_comparison = store_a.merge(store_b, left_on='year', right_on='period', how='outer')
Note that we added the argument how=outer at the end. The image below illustrates the difference between "inner" and "outer" merge:
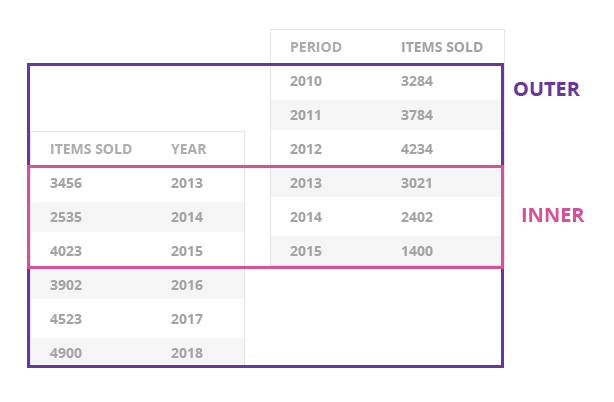
Exercise
Change your code so that it uses an "outer" merge type.
As you can see, we now have all data in place. Missing values have been replaced with NaNs.
Stuck? Here's a hint!
Add: how='outer'.

