Instruction
Let’s analyze another sample query:
SELECT nick, points FROM player WHERE points > 9 ORDER BY points;
The query is a bit different – we no longer use an equality sign in the WHERE clause. Instead, we look for a range of values in the points column. We also want to sort the rows. How can an index on points help achieve that?
In most databases, indexes actually use B+trees. They are very similar to B-trees, but they have an additional feature: each row points to the next row and the previous row. This allows us to easily move from one leaf node (one actual row) to another.
In this case, rows are sorted in ascending order by points:
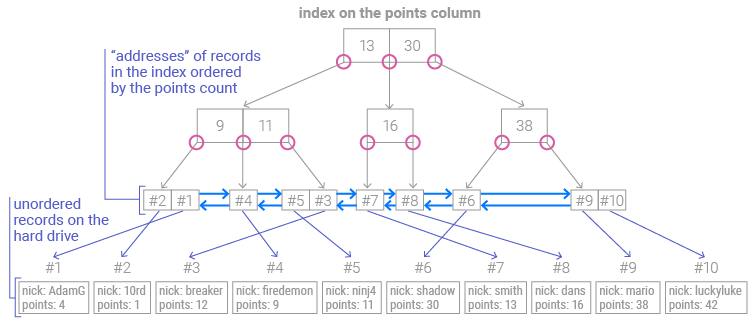
If we want to find the row(s) that satisfy the condition points > 9, we simply need to find the first row with more than nine points:
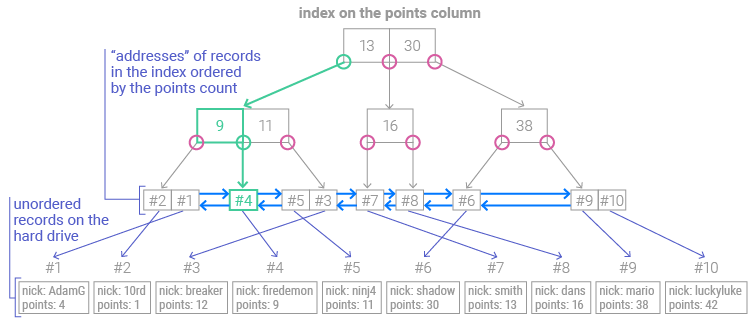
Remember, these rows are sorted in ascending order and contain links to the previous and next row(s). All we need to do is retrieve the remaining rows and show them in the same order in the result set:
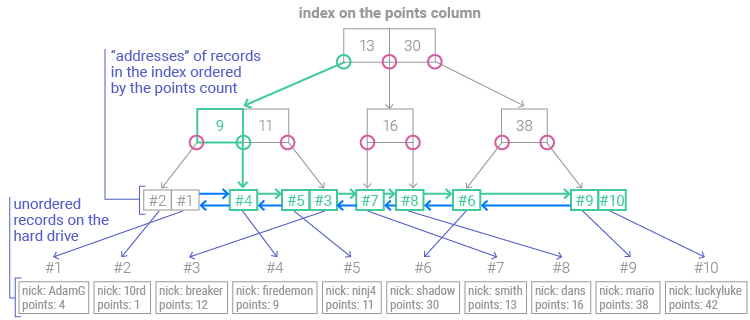
As you can see, we only had to find the first matching row for the given range. After that, this index structure lets us easily move to the next rows. And there was no need to rearrange rows in the result; we showed them in the same order as in the index.
Reading from a B-tree or B+tree index is very quick. But each time you create, modify, or delete a row, you also need to modify the entire tree structure. This takes time and slows down the operation.
Exercise
Click to continue.

