Introduction
Cells
Instruction
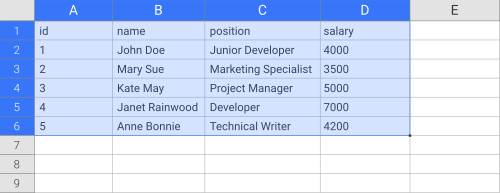
Great! Now let's try something different. Let's assume that we want to access data from a table about employers:
| id | name | position | salary |
|---|---|---|---|
| 1 | John Doe | Junior Developer | 4000 |
| 2 | Mary Sue | Marketing Specialist | 3500 |
| 3 | Kate May | Project Manager | 5000 |
| 4 | Janet Rainwood | Developer | 7000 |
| 5 | Anne Bonnie | Technical Writer | 4200 |
As you can see, this spans from "A1" to "D6":
We can iterate over the values row by row:
ws = wb["employers"] for row in ws["A1":"D6"]: print(row)
The result would be a tuple of cells from each row:
(<Cell "employers".A1>, <Cell "employers".B1>, <Cell "employers".C1>, ...) (<Cell "employers".A2>, <Cell "employers".B2>, <Cell "employers".C2> ...,) (<Cell "employers".A3>, <Cell "employers".B3>, <Cell "employers".C3> ...,)
Each cell object has the name Cell at the beginning, followed by the name of the worksheet it comes from and the A1 notation of its location.
Exercise
Click the button to continue.

