Do you think it's possible to determine what a text document is about? Read on to see how we can use R to programmatically identify the main topics of several South Park seasons and episodes!
In the second article of the series, I showed you how to use R to analyze the differences between South Park characters. I assumed that Eric Cartman is the naughtiest character in the show and tested this hypothesis with real data–check it out to see my conclusion if you haven't already.
In this last article of the series, you'll learn how to identify episode and season topics programmatically. I'll show you a very powerful tool that can help us describe what's going on across different documents. We'll be using data from my southparkr package and the wonderful tidytext package. I'll include most of the code used to create all the tables and plots so you can follow what's going on more easily.
If you haven't watched the show, beware–spoilers ahead!
Let's start by setting up the data you'll be working with:
# Color vectors for use in the plots
character_colors <- c("#F2F32A", "#ED304C", "#F36904", "#57B749", "#51B4BE", "#4F74B1")
vertabelo_color <- "#592a88"
# Data frame where each row is a word spoken by a character
episode_words <- southparkr::process_episode_words(episode_lines, imdb_ratings, keep_stopwords = TRUE) %>%
mutate(
episode_number_str = str_glue("S{stringr::str_pad(season_number, 2, 'left', pad = '0')}E{stringr::str_pad(season_episode_number, 2, 'left', pad = '0')}"),
)
# Data frame where each row is an episode summary
by_episode <- episode_words %>%
group_by(episode_name) %>%
summarize(
total_words = n(),
season_number = season_number[1],
season_episode_number = season_episode_number[1],
episode_number_str = episode_number_str[1],
rating = user_rating[1],
mean_sentiment_score = mean(sentiment_score, na.rm = TRUE)
) %>%
arrange(season_number, season_episode_number) %>%
mutate(episode_order = 1:n())
# This step is needed to include the episode_order column in the episode_words data frame
episode_words <- left_join(
episode_words,
select(by_episode, season_number, season_episode_number, episode_order)
)
What Is TF-IDF Analysis?
Now let me introduce the method we'll be using: TF-IDF, which stands for term frequency-inverse document frequency. Wikipedia offers a nice explanation–it's a numerical statistic that's used to determine the importance of a given word to the context of a document that's part of a larger collection of documents.
Very common English words like the, a, and, etc. (known as stop words) are found in nearly every text. If we were to tally the words in a random document with just raw counts, these words would certainly be at the top.
To give you a better idea of how stop words can be misleading, let's look at the 10 most frequently occurring words in the entirety of South Park:
# Data frame with the 10 most frequent words in South Park
most_freq_words <- episode_words %>%
count(word, sort = TRUE) %>%
mutate(n = prettyNum(n, " ")) %>%
head(10)
| Word | Number of occurrences |
| you | 28 277 |
| the | 27 690 |
| to | 22 228 |
| i | 20 167 |
| a | 17 326 |
| and | 15 201 |
| it | 11 218 |
| is | 10 768 |
| of | 10 658 |
| we | 10 230 |
See? We were right! There are no words with real meaning here that would tell us what the show is actually about. Rather, these words appear frequently simply because they're popular in the English language.
Here's another example to help make this more concrete: Imagine an author who's written several books, perhaps spanning multiple genres. Each book will contain certain words that are unique to its plot and context, but these words likely won't appear in the others. TF-IDF analysis will help us identify these unique words so we can get a better sense for what a document is about.
You'll see this later on in action with South Park–each episode contains unique lines of dialog with different words; TF-IDF will reveal the most important words for each episode. Because I know South Park very well, I'll personally evaluate the results of this analysis to see if it succeeded.
But How Does TF-IDF Work?
Okay, let's be more concrete. TF-IDF penalizes words that appear a lot and in a large number of documents. It's actually a combination of two different metrics, as the name suggests. The first metric is known as term frequency:
$$tf = \frac{number\ of\ term\ occurrences\ in\ a\ document}{total\ number\ of\ words\ in\ a\ document}$$
Simply put, term frequency is how often a given word is used in a document (as a percentage). We'll use the raw count of a word divided by the total number of words in a document to determine this metric. Easy enough, right?
The second part of TF-IDF is inverse document frequency:
$$idf = ln(\frac{n_{documents}}{n_{documents\ containing\ term}})$$
This statistic tells us if a word is rare or very common across a number of documents. For example, if we have 287 episodes of South Park and all 287 of them contain the word the, then our idf will be:
$$idf = ln(\frac{287}{287})=ln(1)=0$$
By multiplying these two metrics together, we get the TF-IDF:
$$tf\_idf = tf * idf$$
Note that the TF-IDF will always be 0 for words that appear in every document, since ln(1) is always 0.
Let's do a concrete example with the word alien. South Park episodes will be our documents; we'll calculate the term frequency for each episode in which the word 'alien' appears. Its inverse document frequency will be a single number. The following table captures all of these results for each episode where the word alien appears.
# Data frame of counts of "alien" word occurrences across episodes
alien <- filter(episode_words, word == "alien") %>%
count(season_number, season_episode_number) %>%
mutate(episode = glue("S{stringr::str_pad(season_number, 2, 'left', pad = '0')}E{stringr::str_pad(season_episode_number, 2, 'left', pad = '0')}")) %>%
select(episode, n_alien = n) %>%
left_join(
by_episode %>% select(episode_number_str, total_words),
by = c("episode" = "episode_number_str")) %>%
# Calculating term frequency
mutate(tf = n_alien / total_words)
# Wrangling alien to include idf and tf_idf columns
alien <- mutate(
alien,
# Calculating inverse document frequency
idf = log(nrow(by_episode) / nrow(alien)),
# Calculating term frequency-inverse document frequency
tf_idf = tf * idf
)
| episode | n_alien | total_words | tf | idf | tf_idf |
| S01E01 | 8 | 3234 | 0.0024737 | 2.886893 | 0.0071414 |
| S01E11 | 1 | 3165 | 0.0003160 | 2.886893 | 0.0009121 |
| S02E07 | 1 | 3100 | 0.0003226 | 2.886893 | 0.0009313 |
| S03E03 | 4 | 3861 | 0.0010360 | 2.886893 | 0.0029908 |
| S03E13 | 6 | 3005 | 0.0019967 | 2.886893 | 0.0057642 |
| S05E05 | 1 | 3991 | 0.0002506 | 2.886893 | 0.0007234 |
| S05E08 | 1 | 3390 | 0.0002950 | 2.886893 | 0.0008516 |
| S05E12 | 1 | 3429 | 0.0002916 | 2.886893 | 0.0008419 |
| S07E01 | 11 | 3225 | 0.0034109 | 2.886893 | 0.0098468 |
| S07E12 | 1 | 3692 | 0.0002709 | 2.886893 | 0.0007819 |
| S09E12 | 6 | 3339 | 0.0017969 | 2.886893 | 0.0051876 |
| S11E11 | 1 | 2811 | 0.0003557 | 2.886893 | 0.0010270 |
| S13E06 | 19 | 2859 | 0.0066457 | 2.886893 | 0.0191854 |
| S14E01 | 14 | 3026 | 0.0046266 | 2.886893 | 0.0133564 |
| S15E13 | 11 | 2947 | 0.0037326 | 2.886893 | 0.0107756 |
| S20E01 | 1 | 3461 | 0.0002889 | 2.886893 | 0.0008341 |
Guessing the Topics of Seasons 18, 19, and 20
I'd like to dive into analyzing these three specific seasons, since each one has a cumulative plot that evolves throughout the episodes. This is something the creators have rarely done in the show-most other episodes stand alone and don't require too much knowledge of the previous ones.
This is perfect for us because we should be able to use TF-IDF to reveal what each season is about! You can imagine that this wouldn't be too meaningful for seasons where each episode has a different plot, right?
Let's examine the most significant words of these seasons in the following bar plot. The TF-IDF x-axis values are multiplied by 1000 so they're more readable.
# Start by counting word occurrences in each season
season_words <- episode_words %>%
count(season_number, word, sort = TRUE)
# Calculate a total number of words for each season
total_words <- season_words %>%
group_by(season_number) %>%
summarize(total = sum(n))
# Join both of the data frames and calculate tf-idf for each word in the season
season_words <- left_join(season_words, total_words) %>%
# Automatically calculate tf-idf using bind_tf_idf from tidytext
bind_tf_idf(word, season_number, n) %>%
arrange(desc(tf_idf))
# Filtered data frame with only top 10 tf-idf words from seasons 18, 19 and 20
our_season_words <- season_words %>%
filter(season_number %in% c(18, 19, 20)) %>%
group_by(season_number) %>%
top_n(10, wt = tf_idf) %>%
arrange(season_number, desc(tf_idf))
# This is a slightly modified our_season_words data frame which
# is needed in order to properly display the following bar plot.
top_n_season_words <- our_season_words %>%
arrange(desc(n)) %>%
group_by(season_number) %>%
top_n(10) %>%
ungroup() %>%
arrange(season_number, tf_idf) %>%
# This is needed for proper bar ordering in facets
# https://drsimonj.svbtle.com/ordering-categories-within-ggplot2-facets
mutate(order = row_number())
# Code to produce the following bar plot
ggplot(top_n_season_words, aes(order, tf_idf*1000, fill = factor(season_number))) +
geom_col(show.legend = FALSE) +
facet_wrap(~ season_number, scales = "free") +
coord_flip() +
labs(
y = "tf-idf * 1000",
x = "Top 10 most significant season topics"
) +
scale_x_continuous(
breaks = top_n_season_words$order,
labels = top_n_season_words$word
) +
scale_fill_manual(values = character_colors[c(2, 4, 6)]) +
theme(panel.grid.minor = element_blank())
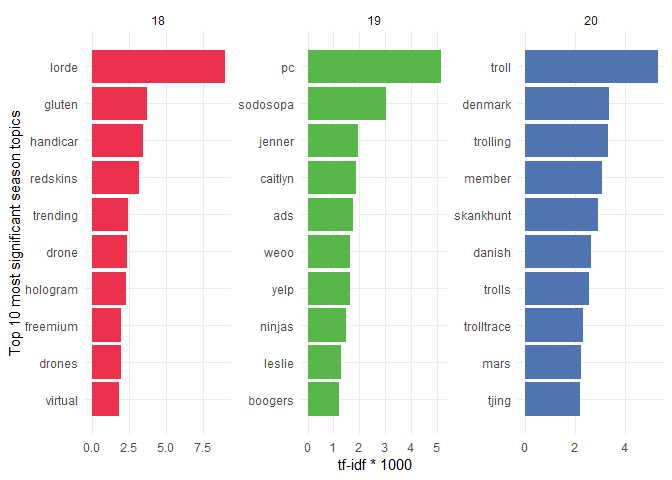
Let's now see how well the analysis turned out. The storyline of Season 18 focuses on Randy Marsh having a musical career as Lorde-and that happens to be the number-one word on our list! They also make fun of gluten-free diets throughout the season. A secondary but nonetheless big focus in this season is on virtual reality.
Season 19 has even stronger messages. It begins with an announcement that there will be a new principal: PC Principal. He starts promoting a PC (politically correct) culture because South Park is obviously full of racists and intolerant people. Mr. Garrison doesn’t take it anymore and starts running for President of the United States alongside his running mate Caitlyn Jenner—a former decathlon Olympic champion, Bruce Jenner, who had a sex change operation. The last important topic of the series is ads that negatively influence everything and even start being indistinguishable from regular people.
In Season 20, it was all about SkankHunt42, Kyle’s dad. He became a troll who enjoyed harassing all sorts of people online. It ended with the fictional Danish Olympic champion Freja Ollegard killing herself. Denmark then created a worldwide service called trolltrace.com that was able to identify any troll online. Eric Cartman also started dating Heidi Turner and tried to get to Mars with the help of Elon Musk’s SpaceX company.
If you compare the bold words with the ones in the bar plot, you’ll see that our TF–IDF analysis did a great job identifying the topics of these seasons! There were also a few words that were picked up that I didn’t mention (like drones or handicar); those were mainly significant in a few episodes, but they made it to the top 10 anyway. But overall, the method did great!
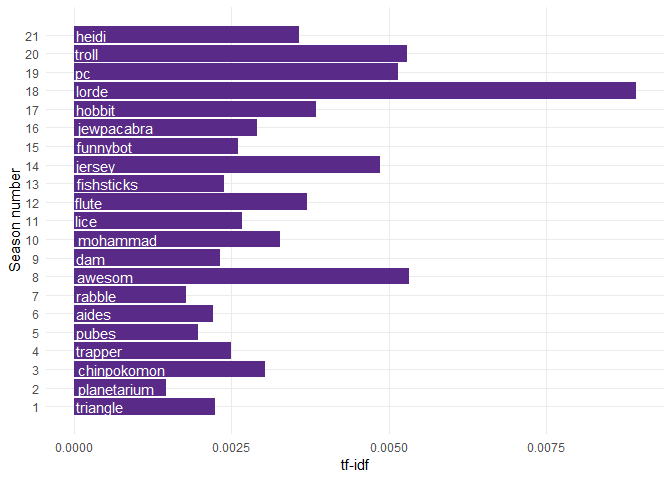
For the sake of completeness, the next bar plot shows you the most significant topic for each season. Just keep in mind that this doesn’t have to be true for the other seasons that we haven’t analyzed that closely, since not all seasons have a single theme:
# Summary data frame with each row being a top tf-idf word in a season
seasons_tf_idf <- season_words %>%
group_by(season_number) %>%
summarize(
tf_idf = max(tf_idf),
word = word[which.max(tf_idf)]
)
# Code to produce the following plot
ggplot(seasons_tf_idf, aes(season_number, tf_idf, label = word)) +
geom_col(fill = vertabelo_color) +
geom_text(aes(y = 0), col = "white", hjust = -.05) +
scale_x_continuous(breaks = 1:21) +
labs(
x = "Season number",
y = "tf-idf"
) +
coord_flip() +
theme(panel.grid.minor = element_blank())
What Are the 3 Most Popular Episodes About?
I’ll do the same plot I did for the three seasons but now for the three most popular episodes (according to IMDB). Because episodes generally have a single, central theme, the results should be more accurate. Let’s find out!
# This code block is very similar to the one above that
# created the top 10 tf-idf words for the three seasons.
# Instead, it shows the top 10 tf-idf words for the 3 most
# popular South Park episodes.
ep_words <- episode_words %>%
count(episode_order, word, sort = TRUE)
ep_total_words <- ep_words %>%
group_by(episode_order) %>%
summarize(total = sum(n))
ep_words <- left_join(ep_words, ep_total_words) %>%
bind_tf_idf(word, episode_order, n) %>%
arrange(desc(tf_idf))
eps_tf_idf <- ep_words %>%
group_by(episode_order) %>%
summarize(
tf_idf = max(tf_idf),
word = word[which.max(tf_idf)]
)
top_episodes <- ep_words %>%
group_by(episode_order) %>%
top_n(10, wt = tf_idf) %>%
arrange(episode_order, desc(tf_idf)) %>%
filter(episode_order %in% c(69, 147, 92))
top_n_episode_words <- top_episodes %>%
arrange(desc(n)) %>%
group_by(episode_order) %>%
top_n(10) %>%
ungroup() %>%
arrange(episode_order, tf_idf) %>%
# This is needed for proper bar ordering in facets
# https://drsimonj.svbtle.com/ordering-categories-within-ggplot2-facets
mutate(order = row_number())
ggplot(top_n_episode_words, aes(order, tf_idf*100, fill = factor(episode_order, labels = c("Scott Tenorman Must Die", "The Return of the Fellowship of the Ring to the Two Towers", "Make Love, Not Warcraft")))) +
geom_col(show.legend = FALSE) +
facet_wrap(~ factor(episode_order, labels = c("Scott Tenorman Must Die", "The Return of the\n Fellowship of the Ring \nto the Two Towers", "Make Love, Not Warcraft")), scales = "free") +
coord_flip() +
labs(
y = "tf-idf * 100",
x = "Top 10 most significant episode topics"
) +
scale_x_continuous(
breaks = top_n_episode_words$order,
labels = top_n_episode_words$word
) +
scale_fill_manual(values = character_colors[c(2, 4, 6)]) +
theme(panel.grid.minor = element_blank())
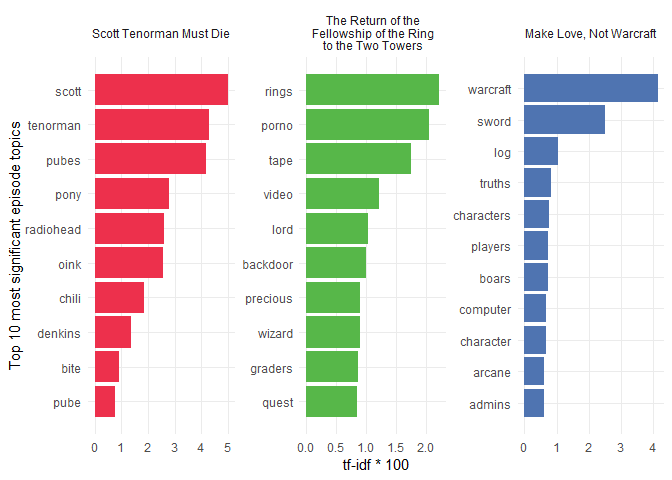
I’ll try to describe each of the three episodes using a few sentences with their true storyline.
- Scott Tenorman Must Die: Scott Tenorman, a ninth grader, sells his pubes to Eric Cartman. Eric later realized that he got tricked and wants to get back at Scott, so he trains Mr. Denkins’s pony to bite off Scott’s wiener. Eric ends up having Scott’s parents killed and serves them to Scott in a chilli con carne at a chilli festival. The episode ends with Scott’s favorite band, Radiohead, coming to the festival and mocking Scott.
- The Return of the Fellowship of the Ring to the Two Towers: Stan’s parents rent a porno video tape called Back Door Sl**s 9 and The Lord of the Rings. The boys are given a quest to deliver the LOTR movie to Butters. The two tapes get mixed up, though, and Butters is given the porno tape instead.
- Make Love, Not Warcraft: The boys play World of Warcraft but encounter a player who’s even stronger than the admins and who starts killing innocent players. Their only way to level up to fight the bully character is to start killing computer-generated boars. Once they level their characters sufficiently, their only chance is to use the sword of a thousand truths to win the fight!
If you know these episodes, you must agree with these amazing results!
Let’s end this section with an overview of the main topics for each of the 287 episodes. You can explore the results in the following interactive plot. I put the IMDB ratings on the y-axis so that you can choose to only explore the popular episodes if you want:
# Wrangled by_episode data frame that includes the top tf-idf
# word for each episode.
by_episode <- inner_join(by_episode, eps_tf_idf) %>%
mutate(text_hover = str_glue("Episode name: {episode_name}
Episode number: {episode_number_str}
IMDB rating: {rating}
Characteristic word: {word}"))
# Creating the following plot
g <- ggplot(by_episode, aes(episode_order, rating)) +
geom_point(aes(text = text_hover), alpha = 0.6, size = 3, col = vertabelo_color) +
labs(
x = "Episode number",
y = "IMDB rating"
)
# Making the following plot interactive
ggplotly(g, tooltip = "text")
{"x":{"data":[{"x":[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,170,171,172,173,174,175,176,177,178,179,180,181,182,183,184,185,186,187,188,189,190,191,192,193,194,195,196,197,198,199,200,201,202,203,204,205,206,207,208,209,210,211,212,213,214,215,216,217,218,219,220,221,222,223,224,225,226,227,228,229,230,231,232,233,234,235,236,237,238,239,240,241,242,243,244,245,246,247,248,249,250,251,252,253,254,255,256,257,258,259,260,261,262,263,264,265,266,267,268,269,270,271,272,273,274,275,276,277,278,279,280,281,282,283,284,285,286,287],"y":[8.2,7.9,7.9,7.8,7.7,8.2,8.5,8.2,8.3,8.1,8.1,7.8,8.7,6.6,8.5,8.2,8.2,7.9,7.8,7.6,7.7,7.8,8.1,7.8,8.1,7.8,8,8.6,8.2,8.5,8.1,8.5,8.3,8.1,6.7,7.8,8.4,8.1,8.2,7.6,8,8.8,8.1,8.2,8.4,7.4,8,8.2,8.3,8.7,8.3,7.5,9,8.2,8.3,8.2,8.4,8.4,8.2,8.2,7.9,7,8.6,8.8,7.6,8.5,8.4,8.4,9.6,7.2,8.9,8.6,8.4,8,8.1,8.3,8.2,8.9,8.9,8.2,8.4,8.1,8.1,8.2,8.6,8.9,8.3,8.4,8.3,8.6,8.8,9.3,8.8,8.7,8.6,8.1,8.5,8.2,8.4,8.2,8.5,8.6,7.7,8.3,9,8.3,9.2,8.9,8.1,8.5,7.8,9.1,8.5,8.7,8.2,9.2,8.7,8.4,8.5,8.7,8.4,8.4,8.6,8.6,9.1,7.7,8.8,7.5,8.7,8.7,9.1,7.7,8.6,8.8,8,8.8,9.1,8.2,7.9,8.2,8.2,8.8,8.8,6.4,8,9,9.5,8.3,8.5,8.1,8.7,8.7,7.4,8.8,8.8,8,8.3,8.3,7.9,8.8,8.9,8,9,9,9,8.4,8.5,7.9,7,8.7,8,7.7,8.6,8.4,7.9,8.6,8.1,7.9,7.8,7.8,7.9,8.2,8.4,8.6,6.5,8.8,7.9,8.2,7.8,8.7,8.3,8.3,8.2,8.2,7.7,7.6,8,8.7,8.8,8.8,8.7,6.9,7.6,8,8.1,8.2,8.4,8.4,8.2,7.6,6.3,6.8,8,7.5,8,8.6,8.1,8.1,7.6,7.9,7.8,7.4,8,7.8,7.9,7.3,6.7,7.6,6.8,8.1,7.5,8.2,8.3,6.6,8.3,7.3,7.5,7.5,8.1,7.8,6.9,7.3,7.8,8.9,8.8,8.8,8.5,7.8,7.8,8.6,7.4,8,8.3,9.1,8.4,7.5,6.9,7.8,8.3,7.7,8.1,8.5,8,8.4,9,8.2,8,8,8.2,8.2,8,7.4,7.5,7.1,7.5,7.5,7,6.6,7.9,7.7,7.3,7.4,7.3,7.4,7.2,7.9,7.1],"text":["Episode name: Cartman Gets an Anal Probe
Episode number: S01E01
IMDB rating: 8.2
Characteristic word: moo","Episode name: Weight Gain 4000
Episode number: S01E02
IMDB rating: 7.9
Characteristic word: kathie","Episode name: Volcano
Episode number: S01E03
IMDB rating: 7.9
Characteristic word: scuzzlebutt","Episode name: Big Gay Al's Big Gay Boat Ride
Episode number: S01E04
IMDB rating: 7.8
Characteristic word: sparky","Episode name: An Elephant Makes Love to a Pig
Episode number: S01E05
IMDB rating: 7.7
Characteristic word: elephant","Episode name: Death
Episode number: S01E06
IMDB rating: 8.2
Characteristic word: grandpa","Episode name: Pinkeye
Episode number: S01E07
IMDB rating: 8.5
Characteristic word: costume","Episode name: Starvin' Marvin
Episode number: S01E08
IMDB rating: 8.2
Characteristic word: marvin","Episode name: Mr. Hankey, the Christmas Poo
Episode number: S01E09
IMDB rating: 8.3
Characteristic word: hankey","Episode name: Damien
Episode number: S01E10
IMDB rating: 8.1
Characteristic word: mega","Episode name: Tom's Rhinoplasty
Episode number: S01E11
IMDB rating: 8.1
Characteristic word: ellen","Episode name: Mecha-Streisand
Episode number: S01E12
IMDB rating: 7.8
Characteristic word: triangle","Episode name: Cartman's Mom is a Dirty Slut
Episode number: S01E13
IMDB rating: 8.7
Characteristic word: stupidest","Episode name: Terrance and Phillip in Not Without My Anus
Episode number: S02E01
IMDB rating: 6.6
Characteristic word: terrance","Episode name: Cartman's Mom is Still a Dirty Slut
Episode number: S02E02
IMDB rating: 8.5
Characteristic word: sail","Episode name: Chickenlover
Episode number: S02E03
IMDB rating: 8.2
Characteristic word: barbrady","Episode name: Ike's Wee Wee
Episode number: S02E04
IMDB rating: 8.2
Characteristic word: bris","Episode name: Conjoined Fetus Lady
Episode number: S02E05
IMDB rating: 7.9
Characteristic word: dodgeball","Episode name: The Mexican Staring Frog of Southern Sri Lanka
Episode number: S02E06
IMDB rating: 7.8
Characteristic word: ned","Episode name: City on the Edge of Forever
Episode number: S02E07
IMDB rating: 7.6
Characteristic word: crabtree","Episode name: Summer Sucks
Episode number: S02E08
IMDB rating: 7.7
Characteristic word: snake","Episode name: Chef's Chocolate Salty Balls
Episode number: S02E09
IMDB rating: 7.8
Characteristic word: hankey","Episode name: Chickenpox
Episode number: S02E10
IMDB rating: 8.1
Characteristic word: chickenpox","Episode name: Roger Ebert Should Lay off the Fatty Foods
Episode number: S02E11
IMDB rating: 7.8
Characteristic word: planetarium","Episode name: Clubhouses
Episode number: S02E12
IMDB rating: 8.1
Characteristic word: clubhouse","Episode name: Cow Days
Episode number: S02E13
IMDB rating: 7.8
Characteristic word: bull","Episode name: Chef Aid
Episode number: S02E14
IMDB rating: 8
Characteristic word: chef","Episode name: Spookyfish
Episode number: S02E15
IMDB rating: 8.6
Characteristic word: hella","Episode name: Merry Christmas Charlie Manson!
Episode number: S02E16
IMDB rating: 8.2
Characteristic word: manson","Episode name: Gnomes
Episode number: S02E17
IMDB rating: 8.5
Characteristic word: underpants","Episode name: Prehistoric Ice Man
Episode number: S02E18
IMDB rating: 8.1
Characteristic word: gorak","Episode name: Rainforest Shmainforest
Episode number: S03E01
IMDB rating: 8.5
Characteristic word: rainforest","Episode name: Spontaneous Combustion
Episode number: S03E02
IMDB rating: 8.3
Characteristic word: combustion","Episode name: The Succubus
Episode number: S03E03
IMDB rating: 8.1
Characteristic word: fitty","Episode name: Jakovasaurs
Episode number: S03E04
IMDB rating: 6.7
Characteristic word: jakov","Episode name: Tweek vs. Craig
Episode number: S03E05
IMDB rating: 7.8
Characteristic word: richard","Episode name: Sexual Harassment Panda
Episode number: S03E06
IMDB rating: 8.4
Characteristic word: panda","Episode name: Cat Orgy
Episode number: S03E07
IMDB rating: 8.1
Characteristic word: wicky","Episode name: Two Guys Naked in a Hot Tub
Episode number: S03E08
IMDB rating: 8.2
Characteristic word: bosley","Episode name: Jewbilee
Episode number: S03E09
IMDB rating: 7.6
Characteristic word: squirts","Episode name: Korn's Groovy Pirate Ghost Mystery
Episode number: S03E10
IMDB rating: 8
Characteristic word: pirate","Episode name: Chinpokomon
Episode number: S03E11
IMDB rating: 8.8
Characteristic word: chinpokomon","Episode name: Hooked on Monkey Fonics
Episode number: S03E12
IMDB rating: 8.1
Characteristic word: rebecca","Episode name: Starvin' Marvin in Space
Episode number: S03E13
IMDB rating: 8.2
Characteristic word: marklar","Episode name: The Red Badge of Gayness
Episode number: S03E14
IMDB rating: 8.4
Characteristic word: reenactment","Episode name: Mr. Hankey's Christmas Classics
Episode number: S03E15
IMDB rating: 7.4
Characteristic word: dreidel","Episode name: Are You There God? It's Me, Jesus
Episode number: S03E16
IMDB rating: 8
Characteristic word: period","Episode name: World Wide Recorder Concert
Episode number: S03E17
IMDB rating: 8.2
Characteristic word: mung","Episode name: The Tooth Fairy Tats 2000
Episode number: S04E01
IMDB rating: 8.3
Characteristic word: tooth","Episode name: Cartman's Silly Hate Crime 2000
Episode number: S04E02
IMDB rating: 8.7
Characteristic word: crime","Episode name: Timmy 2000
Episode number: S04E03
IMDB rating: 8.3
Characteristic word: timmy","Episode name: Quintuplets 2000
Episode number: S04E04
IMDB rating: 7.5
Characteristic word: romania","Episode name: Cartman Joins NAMBLA
Episode number: S04E05
IMDB rating: 9
Characteristic word: nambla","Episode name: Cherokee Hair Tampons
Episode number: S04E06
IMDB rating: 8.2
Characteristic word: kidney","Episode name: Chef Goes Nanners
Episode number: S04E07
IMDB rating: 8.3
Characteristic word: flag","Episode name: Something You Can Do with Your Finger
Episode number: S04E08
IMDB rating: 8.2
Characteristic word: fingerbang","Episode name: Do the Handicapped Go to Hell?
Episode number: S04E09
IMDB rating: 8.4
Characteristic word: huki","Episode name: Probably
Episode number: S04E10
IMDB rating: 8.4
Characteristic word: saddam","Episode name: Fourth Grade
Episode number: S04E11
IMDB rating: 8.2
Characteristic word: grade","Episode name: Trapper Keeper
Episode number: S04E12
IMDB rating: 8.2
Characteristic word: trapper","Episode name: Helen Keller! The Musical
Episode number: S04E13
IMDB rating: 7.9
Characteristic word: gobbles","Episode name: Pip
Episode number: S04E14
IMDB rating: 7
Characteristic word: pip","Episode name: Fat Camp
Episode number: S04E15
IMDB rating: 8.6
Characteristic word: prostitute","Episode name: The Wacky Molestation Adventure
Episode number: S04E16
IMDB rating: 8.8
Characteristic word: provider","Episode name: A Very Crappy Christmas
Episode number: S04E17
IMDB rating: 7.6
Characteristic word: christmas","Episode name: It Hits the Fan
Episode number: S05E01
IMDB rating: 8.5
Characteristic word: shit","Episode name: Cripple Fight
Episode number: S05E02
IMDB rating: 8.4
Characteristic word: scouts","Episode name: Super Best Friends
Episode number: S05E03
IMDB rating: 8.4
Characteristic word: blaine","Episode name: Scott Tenorman Must Die
Episode number: S05E04
IMDB rating: 9.6
Characteristic word: scott","Episode name: Terrance and Phillip: Behind the Blow
Episode number: S05E05
IMDB rating: 7.2
Characteristic word: phillip","Episode name: Cartmanland
Episode number: S05E06
IMDB rating: 8.9
Characteristic word: cartmanland","Episode name: Proper Condom Use
Episode number: S05E07
IMDB rating: 8.6
Characteristic word: condom","Episode name: Towelie
Episode number: S05E08
IMDB rating: 8.4
Characteristic word: towel","Episode name: Osama bin Laden Has Farty Pants
Episode number: S05E09
IMDB rating: 8
Characteristic word: afghanistan","Episode name: How to Eat with Your Butt
Episode number: S05E10
IMDB rating: 8.1
Characteristic word: milk","Episode name: The Entity
Episode number: S05E11
IMDB rating: 8.3
Characteristic word: cousin","Episode name: Here Comes the Neighborhood
Episode number: S05E12
IMDB rating: 8.2
Characteristic word: rich","Episode name: Kenny Dies
Episode number: S05E13
IMDB rating: 8.9
Characteristic word: stem","Episode name: Butters' Very Own Episode
Episode number: S05E14
IMDB rating: 8.9
Characteristic word: bennigan's","Episode name: Jared Has Aides
Episode number: S06E01
IMDB rating: 8.2
Characteristic word: aides","Episode name: Asspen
Episode number: S06E02
IMDB rating: 8.4
Characteristic word: montage","Episode name: Freak Strike
Episode number: S06E03
IMDB rating: 8.1
Characteristic word: maury","Episode name: Fun with Veal
Episode number: S06E04
IMDB rating: 8.1
Characteristic word: veal","Episode name: The New Terrance and Phillip Movie Trailer
Episode number: S06E05
IMDB rating: 8.2
Characteristic word: tugger","Episode name: Professor Chaos
Episode number: S06E06
IMDB rating: 8.6
Characteristic word: chaos","Episode name: The Simpsons Already Did It
Episode number: S06E07
IMDB rating: 8.9
Characteristic word: simpsons","Episode name: Red Hot Catholic Love
Episode number: S06E08
IMDB rating: 8.3
Characteristic word: vatican","Episode name: Free Hat
Episode number: S06E09
IMDB rating: 8.4
Characteristic word: hat","Episode name: Bebe's Boobs Destroy Society
Episode number: S06E10
IMDB rating: 8.3
Characteristic word: bebe","Episode name: Child Abduction is Not Funny
Episode number: S06E11
IMDB rating: 8.6
Characteristic word: rabble","Episode name: A Ladder to Heaven
Episode number: S06E12
IMDB rating: 8.8
Characteristic word: ladder","Episode name: The Return of the Fellowship of the Ring to the Two Towers
Episode number: S06E13
IMDB rating: 9.3
Characteristic word: rings","Episode name: The Death Camp of Tolerance
Episode number: S06E14
IMDB rating: 8.8
Characteristic word: lemmiwinks","Episode name: The Biggest Douche in the Universe
Episode number: S06E15
IMDB rating: 8.7
Characteristic word: edward","Episode name: My Future Self n' Me
Episode number: S06E16
IMDB rating: 8.6
Characteristic word: future","Episode name: Red Sleigh Down
Episode number: S06E17
IMDB rating: 8.1
Characteristic word: christmas","Episode name: Cancelled
Episode number: S07E01
IMDB rating: 8.5
Characteristic word: earthlings","Episode name: Krazy Kripples
Episode number: S07E02
IMDB rating: 8.2
Characteristic word: christopher","Episode name: Toilet Paper
Episode number: S07E03
IMDB rating: 8.4
Characteristic word: toilet","Episode name: I'm a Little Bit Country
Episode number: S07E04
IMDB rating: 8.2
Characteristic word: rabble","Episode name: Fat Butt and Pancake Head
Episode number: S07E05
IMDB rating: 8.5
Characteristic word: lopez","Episode name: Lil' Crime Stoppers
Episode number: S07E06
IMDB rating: 8.6
Characteristic word: detectives","Episode name: Red Man's Greed
Episode number: S07E07
IMDB rating: 7.7
Characteristic word: sars","Episode name: South Park is Gay!
Episode number: S07E08
IMDB rating: 8.3
Characteristic word: metrosexual","Episode name: Christian Rock Hard
Episode number: S07E09
IMDB rating: 9
Characteristic word: album","Episode name: Grey Dawn
Episode number: S07E10
IMDB rating: 8.3
Characteristic word: seniors","Episode name: Casa Bonita
Episode number: S07E11
IMDB rating: 9.2
Characteristic word: bonita","Episode name: All About Mormons
Episode number: S07E12
IMDB rating: 8.9
Characteristic word: dumb","Episode name: Butt Out
Episode number: S07E13
IMDB rating: 8.1
Characteristic word: tobacco","Episode name: Raisins
Episode number: S07E14
IMDB rating: 8.5
Characteristic word: raisins","Episode name: It's Christmas in Canada
Episode number: S07E15
IMDB rating: 7.8
Characteristic word: canada","Episode name: Good Times with Weapons
Episode number: S08E01
IMDB rating: 9.1
Characteristic word: ninja","Episode name: Up the Down Steroid
Episode number: S08E02
IMDB rating: 8.5
Characteristic word: timmah","Episode name: The Passion of the Jew
Episode number: S08E03
IMDB rating: 8.7
Characteristic word: mel","Episode name: You Got F'd in the A
Episode number: S08E04
IMDB rating: 8.2
Characteristic word: served","Episode name: AWESOM-O
Episode number: S08E05
IMDB rating: 9.2
Characteristic word: awesom","Episode name: The Jeffersons
Episode number: S08E06
IMDB rating: 8.7
Characteristic word: blanket","Episode name: Goobacks
Episode number: S08E07
IMDB rating: 8.4
Characteristic word: future","Episode name: Douche and Turd
Episode number: S08E08
IMDB rating: 8.5
Characteristic word: vote","Episode name: Something Wall-Mart This Way Comes
Episode number: S08E09
IMDB rating: 8.7
Characteristic word: mart","Episode name: Pre-School
Episode number: S08E10
IMDB rating: 8.4
Characteristic word: trent","Episode name: Quest for Ratings
Episode number: S08E11
IMDB rating: 8.4
Characteristic word: cough","Episode name: Stupid Spoiled Whore Video Playset
Episode number: S08E12
IMDB rating: 8.6
Characteristic word: paris","Episode name: Cartman's Incredible Gift
Episode number: S08E13
IMDB rating: 8.6
Characteristic word: psychic","Episode name: Woodland Critter Christmas
Episode number: S08E14
IMDB rating: 9.1
Characteristic word: antichrist","Episode name: Mr. Garrison's Fancy New Vagina
Episode number: S09E01
IMDB rating: 7.7
Characteristic word: dolphin","Episode name: Die Hippie, Die
Episode number: S09E02
IMDB rating: 8.8
Characteristic word: hippies","Episode name: Wing
Episode number: S09E03
IMDB rating: 7.5
Characteristic word: wing","Episode name: Best Friends Forever
Episode number: S09E04
IMDB rating: 8.7
Characteristic word: psp","Episode name: The Losing Edge
Episode number: S09E05
IMDB rating: 8.7
Characteristic word: strike","Episode name: The Death of Eric Cartman
Episode number: S09E06
IMDB rating: 9.1
Characteristic word: lu","Episode name: Erection Day
Episode number: S09E07
IMDB rating: 7.7
Characteristic word: jimmy","Episode name: Two Days Before the Day After Tomorrow
Episode number: S09E08
IMDB rating: 8.6
Characteristic word: dam","Episode name: Marjorine
Episode number: S09E09
IMDB rating: 8.8
Characteristic word: marjorine","Episode name: Follow That Egg!
Episode number: S09E10
IMDB rating: 8
Characteristic word: egg","Episode name: Ginger Kids
Episode number: S09E11
IMDB rating: 8.8
Characteristic word: ginger","Episode name: Trapped in the Closet
Episode number: S09E12
IMDB rating: 9.1
Characteristic word: hubbard","Episode name: Free Willzyx
Episode number: S09E13
IMDB rating: 8.2
Characteristic word: whale","Episode name: Bloody Mary
Episode number: S09E14
IMDB rating: 7.9
Characteristic word: ichi","Episode name: The Return of Chef!
Episode number: S10E01
IMDB rating: 8.2
Characteristic word: chef","Episode name: Smug Alert!
Episode number: S10E02
IMDB rating: 8.2
Characteristic word: smug","Episode name: Cartoon Wars Part I
Episode number: S10E03
IMDB rating: 8.8
Characteristic word: mohammad","Episode name: Cartoon Wars Part II
Episode number: S10E04
IMDB rating: 8.8
Characteristic word: mohammad","Episode name: A Million Little Fibers
Episode number: S10E05
IMDB rating: 6.4
Characteristic word: towel","Episode name: ManBearPig
Episode number: S10E06
IMDB rating: 8
Characteristic word: manbearpig","Episode name: Tsst
Episode number: S10E07
IMDB rating: 9
Characteristic word: tsst","Episode name: Make Love, Not Warcraft
Episode number: S10E08
IMDB rating: 9.5
Characteristic word: warcraft","Episode name: Mystery of the Urinal Deuce
Episode number: S10E09
IMDB rating: 8.3
Characteristic word: urinal","Episode name: Miss Teacher Bangs a Boy
Episode number: S10E10
IMDB rating: 8.5
Characteristic word: monitor","Episode name: Hell on Earth 2006
Episode number: S10E11
IMDB rating: 8.1
Characteristic word: smalls","Episode name: Go God Go
Episode number: S10E12
IMDB rating: 8.7
Characteristic word: wii","Episode name: Go God Go XII
Episode number: S10E13
IMDB rating: 8.7
Characteristic word: bark","Episode name: Stanley's Cup
Episode number: S10E14
IMDB rating: 7.4
Characteristic word: coach","Episode name: With Apologies to Jesse Jackson
Episode number: S11E01
IMDB rating: 8.8
Characteristic word: nigger","Episode name: Cartman Sucks
Episode number: S11E02
IMDB rating: 8.8
Characteristic word: picture","Episode name: Lice Capades
Episode number: S11E03
IMDB rating: 8
Characteristic word: lice","Episode name: The Snuke
Episode number: S11E04
IMDB rating: 8.3
Characteristic word: detonator","Episode name: Fantastic Easter Special
Episode number: S11E05
IMDB rating: 8.3
Characteristic word: rabbit","Episode name: D-Yikes!
Episode number: S11E06
IMDB rating: 7.9
Characteristic word: persians","Episode name: Night of the Living Homeless
Episode number: S11E07
IMDB rating: 8.8
Characteristic word: homeless","Episode name: Le Petit Tourette
Episode number: S11E08
IMDB rating: 8.9
Characteristic word: tourette's","Episode name: More Crap
Episode number: S11E09
IMDB rating: 8
Characteristic word: bono","Episode name: Imaginationland
Episode number: S11E10
IMDB rating: 9
Characteristic word: leprechaun","Episode name: Imaginationland, Episode II
Episode number: S11E11
IMDB rating: 9
Characteristic word: snarf","Episode name: Imaginationland, Episode III
Episode number: S11E12
IMDB rating: 9
Characteristic word: imaginary","Episode name: Guitar Queer-O
Episode number: S11E13
IMDB rating: 8.4
Characteristic word: hero","Episode name: The List
Episode number: S11E14
IMDB rating: 8.5
Characteristic word: list","Episode name: Tonsil Trouble
Episode number: S12E01
IMDB rating: 7.9
Characteristic word: hiv","Episode name: Britney's New Look
Episode number: S12E02
IMDB rating: 7
Characteristic word: britney","Episode name: Major Boobage
Episode number: S12E03
IMDB rating: 8.7
Characteristic word: cheesing","Episode name: Canada on Strike
Episode number: S12E04
IMDB rating: 8
Characteristic word: canada","Episode name: Eek, A Penis!
Episode number: S12E05
IMDB rating: 7.7
Characteristic word: penis","Episode name: Over Logging
Episode number: S12E06
IMDB rating: 8.6
Characteristic word: internet","Episode name: Super Fun Time
Episode number: S12E07
IMDB rating: 8.4
Characteristic word: pioneer","Episode name: The China Probrem
Episode number: S12E08
IMDB rating: 7.9
Characteristic word: chinese","Episode name: Breast Cancer Show Ever
Episode number: S12E09
IMDB rating: 8.6
Characteristic word: wendy","Episode name: Pandemic
Episode number: S12E10
IMDB rating: 8.1
Characteristic word: flute","Episode name: Pandemic 2: The Startling
Episode number: S12E11
IMDB rating: 7.9
Characteristic word: guinea","Episode name: About Last Night...
Episode number: S12E12
IMDB rating: 7.8
Characteristic word: obama","Episode name: Elementary School Musical
Episode number: S12E13
IMDB rating: 7.8
Characteristic word: bridon","Episode name: The Ungroundable
Episode number: S12E14
IMDB rating: 7.9
Characteristic word: vampire","Episode name: The Ring
Episode number: S13E01
IMDB rating: 8.2
Characteristic word: purity","Episode name: The Coon
Episode number: S13E02
IMDB rating: 8.4
Characteristic word: mysterion","Episode name: Margaritaville
Episode number: S13E03
IMDB rating: 8.6
Characteristic word: economy","Episode name: Eat, Pray, Queef
Episode number: S13E04
IMDB rating: 6.5
Characteristic word: queef","Episode name: Fishsticks
Episode number: S13E05
IMDB rating: 8.8
Characteristic word: fishsticks","Episode name: Pinewood Derby
Episode number: S13E06
IMDB rating: 7.9
Characteristic word: derby","Episode name: Fatbeard
Episode number: S13E07
IMDB rating: 8.2
Characteristic word: pirates","Episode name: Dead Celebrities
Episode number: S13E08
IMDB rating: 7.8
Characteristic word: mays","Episode name: Butters' Bottom Bitch
Episode number: S13E09
IMDB rating: 8.7
Characteristic word: pimp","Episode name: W.T.F.
Episode number: S13E10
IMDB rating: 8.3
Characteristic word: wrestling","Episode name: Whale Whores
Episode number: S13E11
IMDB rating: 8.3
Characteristic word: japanese","Episode name: The F Word
Episode number: S13E12
IMDB rating: 8.2
Characteristic word: fags","Episode name: Dances with Smurfs
Episode number: S13E13
IMDB rating: 8.2
Characteristic word: smurfs","Episode name: Pee
Episode number: S13E14
IMDB rating: 7.7
Characteristic word: pee","Episode name: Sexual Healing
Episode number: S14E01
IMDB rating: 7.6
Characteristic word: addiction","Episode name: The Tale of Scrotie McBoogerballs
Episode number: S14E02
IMDB rating: 8
Characteristic word: book","Episode name: Medicinal Fried Chicken
Episode number: S14E03
IMDB rating: 8.7
Characteristic word: kfc","Episode name: You Have 0 Friends
Episode number: S14E04
IMDB rating: 8.8
Characteristic word: facebook","Episode name: 200
Episode number: S14E05
IMDB rating: 8.8
Characteristic word: muhammad","Episode name: 201
Episode number: S14E06
IMDB rating: 8.7
Characteristic word: muhammad","Episode name: Crippled Summer
Episode number: S14E07
IMDB rating: 6.9
Characteristic word: towelie","Episode name: Poor and Stupid
Episode number: S14E08
IMDB rating: 7.6
Characteristic word: nascar","Episode name: It's a Jersey Thing
Episode number: S14E09
IMDB rating: 8
Characteristic word: jersey","Episode name: Insheeption
Episode number: S14E10
IMDB rating: 8.1
Characteristic word: hoarding","Episode name: Coon 2: Hindsight
Episode number: S14E11
IMDB rating: 8.2
Characteristic word: coon","Episode name: Mysterion Rises
Episode number: S14E12
IMDB rating: 8.4
Characteristic word: cthulhu","Episode name: Coon vs. Coon & Friends
Episode number: S14E13
IMDB rating: 8.4
Characteristic word: coon","Episode name: Creme Fraiche
Episode number: S14E14
IMDB rating: 8.2
Characteristic word: fra�che","Episode name: HUMANCENTiPAD
Episode number: S15E01
IMDB rating: 7.6
Characteristic word: apple","Episode name: Funnybot
Episode number: S15E02
IMDB rating: 6.3
Characteristic word: funnybot","Episode name: Royal Pudding
Episode number: S15E03
IMDB rating: 6.8
Characteristic word: decay","Episode name: T.M.I.
Episode number: S15E04
IMDB rating: 8
Characteristic word: inches","Episode name: Crack Baby Athletic Association
Episode number: S15E05
IMDB rating: 7.5
Characteristic word: crack","Episode name: City Sushi
Episode number: S15E06
IMDB rating: 8
Characteristic word: janus","Episode name: You're Getting Old
Episode number: S15E07
IMDB rating: 8.6
Characteristic word: tween","Episode name: Ass Burgers
Episode number: S15E08
IMDB rating: 8.1
Characteristic word: asperger's","Episode name: The Last of the Meheecans
Episode number: S15E09
IMDB rating: 8.1
Characteristic word: mantequilla","Episode name: Bass to Mouth
Episode number: S15E10
IMDB rating: 7.6
Characteristic word: lemmiwinks","Episode name: Broadway Bro Down
Episode number: S15E11
IMDB rating: 7.9
Characteristic word: blowjob","Episode name: 1%
Episode number: S15E12
IMDB rating: 7.8
Characteristic word: 99","Episode name: A History Channel Thanksgiving
Episode number: S15E13
IMDB rating: 7.4
Characteristic word: stuffing","Episode name: The Poor Kid
Episode number: S15E14
IMDB rating: 8
Characteristic word: penn","Episode name: Reverse Cowgirl
Episode number: S16E01
IMDB rating: 7.8
Characteristic word: toilet","Episode name: Cash For Gold
Episode number: S16E02
IMDB rating: 7.9
Characteristic word: jewelry","Episode name: Faith Hilling
Episode number: S16E03
IMDB rating: 7.3
Characteristic word: hilling","Episode name: Jewpacabra
Episode number: S16E04
IMDB rating: 6.7
Characteristic word: jewpacabra","Episode name: Butterballs
Episode number: S16E05
IMDB rating: 7.6
Characteristic word: bullying","Episode name: I Should Have Never Gone Ziplining
Episode number: S16E06
IMDB rating: 6.8
Characteristic word: ziplining","Episode name: Cartman Finds Love
Episode number: S16E07
IMDB rating: 8.1
Characteristic word: nichole","Episode name: Sarcastaball
Episode number: S16E08
IMDB rating: 7.5
Characteristic word: sarcastaball","Episode name: Raising the Bar
Episode number: S16E09
IMDB rating: 8.2
Characteristic word: boo","Episode name: Insecurity
Episode number: S16E10
IMDB rating: 8.3
Characteristic word: insecurity","Episode name: Going Native
Episode number: S16E11
IMDB rating: 6.6
Characteristic word: haoles","Episode name: A Nightmare on Face Time
Episode number: S16E12
IMDB rating: 8.3
Characteristic word: blockbuster","Episode name: A Scause For Applause
Episode number: S16E13
IMDB rating: 7.3
Characteristic word: bracelet","Episode name: Obama Wins!
Episode number: S16E14
IMDB rating: 7.5
Characteristic word: ballots","Episode name: Let Go, Let Gov
Episode number: S17E01
IMDB rating: 7.5
Characteristic word: dmv","Episode name: Informative Murder Porn
Episode number: S17E02
IMDB rating: 8.1
Characteristic word: minecraft","Episode name: World War Zimmerman
Episode number: S17E03
IMDB rating: 7.8
Characteristic word: zimmerman","Episode name: Goth Kids 3: Dawn of the Posers
Episode number: S17E04
IMDB rating: 6.9
Characteristic word: emo","Episode name: Taming Strange
Episode number: S17E05
IMDB rating: 7.3
Characteristic word: intellilink","Episode name: Ginger Cow
Episode number: S17E06
IMDB rating: 7.8
Characteristic word: yummy","Episode name: Black Friday
Episode number: S17E07
IMDB rating: 8.9
Characteristic word: friday","Episode name: A Song of Ass and Fire
Episode number: S17E08
IMDB rating: 8.8
Characteristic word: wiener","Episode name: Titties and Dragons
Episode number: S17E09
IMDB rating: 8.8
Characteristic word: kenni","Episode name: The Hobbit
Episode number: S17E10
IMDB rating: 8.5
Characteristic word: hobbit","Episode name: Go Fund Yourself
Episode number: S18E01
IMDB rating: 7.8
Characteristic word: redskins","Episode name: Gluten Free Ebola
Episode number: S18E02
IMDB rating: 7.8
Characteristic word: gluten","Episode name: The Cissy
Episode number: S18E03
IMDB rating: 8.6
Characteristic word: lorde","Episode name: Handicar
Episode number: S18E04
IMDB rating: 7.4
Characteristic word: handicar","Episode name: The Magic Bush
Episode number: S18E05
IMDB rating: 8
Characteristic word: drone","Episode name: Freemium Isn't Free
Episode number: S18E06
IMDB rating: 8.3
Characteristic word: freemium","Episode name: Grounded Vindaloop
Episode number: S18E07
IMDB rating: 9.1
Characteristic word: virtual","Episode name: Cock Magic
Episode number: S18E08
IMDB rating: 8.4
Characteristic word: mcnuggets","Episode name: #REHASH
Episode number: S18E09
IMDB rating: 7.5
Characteristic word: lorde","Episode name: #HappyHolograms
Episode number: S18E10
IMDB rating: 6.9
Characteristic word: trending","Episode name: Stunning and Brave
Episode number: S19E01
IMDB rating: 7.8
Characteristic word: pc","Episode name: Where My Country Gone?
Episode number: S19E02
IMDB rating: 8.3
Characteristic word: usa","Episode name: The City Part of Town
Episode number: S19E03
IMDB rating: 7.7
Characteristic word: sodosopa","Episode name: You're Not Yelping
Episode number: S19E04
IMDB rating: 8.1
Characteristic word: yelp","Episode name: Safe Space
Episode number: S19E05
IMDB rating: 8.5
Characteristic word: spaaaace","Episode name: Tweek x Craig
Episode number: S19E06
IMDB rating: 8
Characteristic word: tweek","Episode name: Naughty Ninjas
Episode number: S19E07
IMDB rating: 8.4
Characteristic word: ninjas","Episode name: Sponsored Content
Episode number: S19E08
IMDB rating: 9
Characteristic word: ad","Episode name: Truth and Advertising
Episode number: S19E09
IMDB rating: 8.2
Characteristic word: ads","Episode name: PC Principal Final Justice
Episode number: S19E10
IMDB rating: 8
Characteristic word: pc","Episode name: Member Berries
Episode number: S20E01
IMDB rating: 8
Characteristic word: member","Episode name: Skank Hunt
Episode number: S20E02
IMDB rating: 8.2
Characteristic word: twitter","Episode name: The Damned
Episode number: S20E03
IMDB rating: 8.2
Characteristic word: member","Episode name: Wieners Out
Episode number: S20E04
IMDB rating: 8
Characteristic word: trolls","Episode name: Douche and a Danish
Episode number: S20E05
IMDB rating: 7.4
Characteristic word: denmark","Episode name: Fort Collins
Episode number: S20E06
IMDB rating: 7.5
Characteristic word: member","Episode name: Oh, Jeez
Episode number: S20E07
IMDB rating: 7.1
Characteristic word: ambassador","Episode name: Members Only
Episode number: S20E08
IMDB rating: 7.5
Characteristic word: member","Episode name: Not Funny
Episode number: S20E09
IMDB rating: 7.5
Characteristic word: denmark","Episode name: The End of Serialization as We Know It
Episode number: S20E10
IMDB rating: 7
Characteristic word: elon","Episode name: White People Renovating Houses
Episode number: S21E01
IMDB rating: 6.6
Characteristic word: alexa","Episode name: Put It Down
Episode number: S21E02
IMDB rating: 7.9
Characteristic word: korea","Episode name: Holiday Special
Episode number: S21E03
IMDB rating: 7.7
Characteristic word: columbus","Episode name: Franchise Prequel
Episode number: S21E04
IMDB rating: 7.3
Characteristic word: zuckerberg","Episode name: Hummels & Heroin
Episode number: S21E05
IMDB rating: 7.4
Characteristic word: hummels","Episode name: Sons A Witches
Episode number: S21E06
IMDB rating: 7.3
Characteristic word: witch","Episode name: Doubling Down
Episode number: S21E07
IMDB rating: 7.4
Characteristic word: heidi","Episode name: Moss Piglets
Episode number: S21E08
IMDB rating: 7.2
Characteristic word: science","Episode name: SUPER HARD PCness
Episode number: S21E09
IMDB rating: 7.9
Characteristic word: m'alright","Episode name: Splatty Tomato
Episode number: S21E10
IMDB rating: 7.1
Characteristic word: whites"],"type":"scatter","mode":"markers","marker":{"autocolorscale":false,"color":"rgba(89,42,136,1)","opacity":0.6,"size":11.3385826771654,"symbol":"circle","line":{"width":1.88976377952756,"color":"rgba(89,42,136,1)"}},"hoveron":"points","showlegend":false,"xaxis":"x","yaxis":"y","hoverinfo":"text","frame":null}],"layout":{"margin":{"t":26.2283105022831,"r":7.30593607305936,"b":40.1826484018265,"l":31.4155251141553},"font":{"color":"rgba(0,0,0,1)","family":"","size":14.6118721461187},"xaxis":{"domain":[0,1],"automargin":true,"type":"linear","autorange":false,"range":[-13.3,301.3],"tickmode":"array","ticktext":["0","100","200","300"],"tickvals":[0,100,200,300],"categoryorder":"array","categoryarray":["0","100","200","300"],"nticks":null,"ticks":"","tickcolor":null,"ticklen":3.65296803652968,"tickwidth":0,"showticklabels":true,"tickfont":{"color":"rgba(77,77,77,1)","family":"","size":11.689497716895},"tickangle":-0,"showline":false,"linecolor":null,"linewidth":0,"showgrid":true,"gridcolor":"rgba(235,235,235,1)","gridwidth":0.66417600664176,"zeroline":false,"anchor":"y","title":"Episode number","titlefont":{"color":"rgba(0,0,0,1)","family":"","size":14.6118721461187},"hoverformat":".2f"},"yaxis":{"domain":[0,1],"automargin":true,"type":"linear","autorange":false,"range":[6.135,9.765],"tickmode":"array","ticktext":["7","8","9"],"tickvals":[7,8,9],"categoryorder":"array","categoryarray":["7","8","9"],"nticks":null,"ticks":"","tickcolor":null,"ticklen":3.65296803652968,"tickwidth":0,"showticklabels":true,"tickfont":{"color":"rgba(77,77,77,1)","family":"","size":11.689497716895},"tickangle":-0,"showline":false,"linecolor":null,"linewidth":0,"showgrid":true,"gridcolor":"rgba(235,235,235,1)","gridwidth":0.66417600664176,"zeroline":false,"anchor":"x","title":"IMDB rating","titlefont":{"color":"rgba(0,0,0,1)","family":"","size":14.6118721461187},"hoverformat":".2f"},"shapes":[{"type":"rect","fillcolor":null,"line":{"color":null,"width":0,"linetype":[]},"yref":"paper","xref":"paper","x0":0,"x1":1,"y0":0,"y1":1}],"showlegend":false,"legend":{"bgcolor":null,"bordercolor":null,"borderwidth":0,"font":{"color":"rgba(0,0,0,1)","family":"","size":11.689497716895}},"hovermode":"closest","barmode":"relative"},"config":{"doubleClick":"reset","modeBarButtonsToAdd":[{"name":"Collaborate","icon":{"width":1000,"ascent":500,"descent":-50,"path":"M487 375c7-10 9-23 5-36l-79-259c-3-12-11-23-22-31-11-8-22-12-35-12l-263 0c-15 0-29 5-43 15-13 10-23 23-28 37-5 13-5 25-1 37 0 0 0 3 1 7 1 5 1 8 1 11 0 2 0 4-1 6 0 3-1 5-1 6 1 2 2 4 3 6 1 2 2 4 4 6 2 3 4 5 5 7 5 7 9 16 13 26 4 10 7 19 9 26 0 2 0 5 0 9-1 4-1 6 0 8 0 2 2 5 4 8 3 3 5 5 5 7 4 6 8 15 12 26 4 11 7 19 7 26 1 1 0 4 0 9-1 4-1 7 0 8 1 2 3 5 6 8 4 4 6 6 6 7 4 5 8 13 13 24 4 11 7 20 7 28 1 1 0 4 0 7-1 3-1 6-1 7 0 2 1 4 3 6 1 1 3 4 5 6 2 3 3 5 5 6 1 2 3 5 4 9 2 3 3 7 5 10 1 3 2 6 4 10 2 4 4 7 6 9 2 3 4 5 7 7 3 2 7 3 11 3 3 0 8 0 13-1l0-1c7 2 12 2 14 2l218 0c14 0 25-5 32-16 8-10 10-23 6-37l-79-259c-7-22-13-37-20-43-7-7-19-10-37-10l-248 0c-5 0-9-2-11-5-2-3-2-7 0-12 4-13 18-20 41-20l264 0c5 0 10 2 16 5 5 3 8 6 10 11l85 282c2 5 2 10 2 17 7-3 13-7 17-13z m-304 0c-1-3-1-5 0-7 1-1 3-2 6-2l174 0c2 0 4 1 7 2 2 2 4 4 5 7l6 18c0 3 0 5-1 7-1 1-3 2-6 2l-173 0c-3 0-5-1-8-2-2-2-4-4-4-7z m-24-73c-1-3-1-5 0-7 2-2 3-2 6-2l174 0c2 0 5 0 7 2 3 2 4 4 5 7l6 18c1 2 0 5-1 6-1 2-3 3-5 3l-174 0c-3 0-5-1-7-3-3-1-4-4-5-6z"},"click":"function(gd) { \n // is this being viewed in RStudio?\n if (location.search == '?viewer_pane=1') {\n alert('To learn about plotly for collaboration, visit:\\n https://cpsievert.github.io/plotly_book/plot-ly-for-collaboration.html');\n } else {\n window.open('https://cpsievert.github.io/plotly_book/plot-ly-for-collaboration.html', '_blank');\n }\n }"}],"cloud":false},"source":"A","attrs":{"3f28516522d0":{"text":{},"x":{},"y":{},"type":"scatter"}},"cur_data":"3f28516522d0","visdat":{"3f28516522d0":["function (y) ","x"]},"highlight":{"on":"plotly_click","persistent":false,"dynamic":false,"selectize":false,"opacityDim":0.2,"selected":{"opacity":1},"debounce":0},"base_url":"https://plot.ly"},"evals":["config.modeBarButtonsToAdd.0.click"],"jsHooks":[]}
The End of the Series
Well, it’s been a real pleasure! This was the last article from the South Park text mining series, and I’ve had a lot of fun exploring this data with you! Let’s recap what we’ve learned to date:
- I showed you where to get all the South Park dialog.
- You learned how to create a dataset of words from spoken lines. This tidy data format helps you perform powerful data analysis more easily.
- You used ggplot2 to create very informative plots, some of them even interactive thanks to the plotly package.
- You even used a statistical proportion test to compare characters to see who is the naughtiest one, for example.
The last piece of knowledge you gained is how to identify document topics using TF–IDF analysis. It’s definitely a more sophisticated method than just using a raw count of words, which would inaccurately include stop words like “an” and “the.”
You also saw most of the code alongside the text. There are a few bits that I intentionally omitted. To see all of the code, visit my Github page as usual.
As always, reach out to me if you need any help with data analysis!
Patrik out.







